特許翻訳特化型LLM開発:京大発スタートアップのエムニと日本特許翻訳株式会社、GPT-4を超える性能達成
特許翻訳特化型LLM開発でGPT-4を超える性能を達成
京都大学から生まれたスタートアップ、株式会社エムニは、日本特許翻訳株式会社と協力し、特許翻訳に特化した大規模言語モデル(LLM)を開発しました。このモデルは、Meta社が開発したLlama-3-70Bを基に作られ、特定の分野に対するファインチューニングが行われています。その結果、同じような機能を持つDeepLやGPT-4などの既存のモデルを凌駕する性能を達成することができました。特許を翻訳する機会は多いが、それは高額の費用と多くの時間を必要とします。新開発されたこのモデルは、それらの問題を解決する道を開きます。
この記事の要約
- 京都大学発のスタートアップ株式会社エムニと日本特許翻訳株式会社が共同で新しい大規模言語モデルを開発。
- Meta社が開発した言語モデルを基に、特許翻訳特化型のLLMが開発され、DeepLやGPT-4を超える性能を達成。
- 特許翻訳に関わる高額な費用や時間を短縮する可能性を持つ。

■ 概要
京都大学発兼、松尾研発スタートアップ株式会社エムニ(本社:東京都文京区、代表取締役社長:下野祐太)は、日本特許翻訳株式会社(本社:東京都中央区、代表取締役社長:本間奬)と共同で、Meta社が開発した大規模言語モデル(以下、LLM)『Llama-3-70B』をベースに、ファインチューニングを用いた特定分野における特許翻訳特化型LLMの開発に取り組みました。
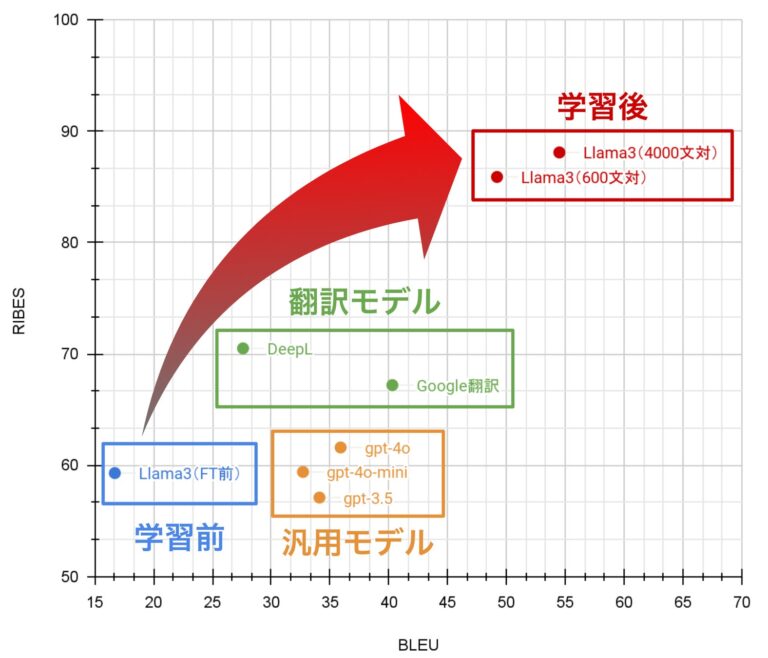
その成果として、GPT-4oをはじめとする汎用的なLLM及びDeepLのような翻訳モデルを大幅に凌駕する性能を達成しました。
今後、より大規模なデータセットを用いた学習やIntelligenceの向上といった取り組みを進めていく予定です。
■ 背景
製造業をはじめとする多くの業界において、特許を翻訳する機会は多く存在しています。例えば特許権を外国で取得する場合は、特許明細書や特許庁への回答書を英語に翻訳する必要があり、また逆に外国の特許文献を調査する場合は、その内容を日本語に翻訳して調査を進める必要があります。
しかしながらこのような外国特許を人手で翻訳する場合、外国公報1件当たり10万円以上の費用と多くの時間を要します。
そういった課題に対して、昨今コストを抑えられるAIによる機械翻訳が注目されています。例えば高い翻訳性能を有した「Google翻訳」や「DeepL」といったツールは特許に限らず様々な場面で利用されており、LLMも翻訳業務での活用が期待されています。
しかしながら既存のツールや汎用的なLLMの場合、特定分野の特許内で用いられる独特な単語や表現に対応することができず、期待する精度を残すことができないという課題に直面しています。
そこで今回当社は特許翻訳のエキスパートである日本特許翻訳株式会社と共同で、Meta社が開発した『Llama-3-70B』をベースに、特定分野において人手で作成した特許翻訳文のペアを用いて、ファインチューニングという追加学習を実施しました。
■ 実験条件
学習データ
人手で翻訳を行った特許翻訳文対の600ペア及び4000ペアを学習データとして利用。
以下、学習データの例
翻訳前:The non-transitory computer-readable recording medium according to claim 2, wherein the process further includes calculating the increase in the number of operating circuits per prescribed time period, based on history regarding the operating status table created within the prescribed time period.
翻訳後:前記所定時間の前記動作状態テーブルの履歴に基づいて前記所定時間当たりの前記動作回路の増加数を算出する、処理を前記コンピュータに実行させる請求項2に記載の制御プログラム。
実行環境
CPU:Intel(R) Xeon(R) CPU E5-2687W
メモリ:125GB
GPU:NVIDIA RTX A6000 48GB ×2
評価指標
機械翻訳で一般的に利用される「BLEU」・「RIBES」を用いて評価を実施。
-
BLEU
機械翻訳の出力と人間が作成した参照訳との間で、Nグラムが一致した数で算出。一般的に40〜50で高品質な翻訳であると言われる。『訳語の適切性』と『訳語の過不足の有無』を評価できる。 -
RIBES
機械翻訳の出力と人間が作成した参照訳との間で、共通して出現する単語の出現順序に基づいて算出。『語順の正確さ』を評価する事ができる。
使用したプロンプト
zero-shotで翻訳を指示するプロンプトを使用。
■ 結果

特定分野の特許翻訳600文対並びに4000文対を用いてファインチューニングを実施した結果、『Llama-3-70B』の特許翻訳性能を大幅に向上させることに成功しました。その結果、BLEU・RIBES両評価指標において、DeepLやGoogle翻訳といった翻訳モデル及びGPT-4oを始めとする汎用的なLLMを凌駕する特許翻訳性能を達成しました。
■ 終わりに
本取り組みを踏まえ、当社は今後以下の2つの開発並びに支援をより一層強化していく所存です。
-
ファインチューニングを用いた独自LLMの開発
本取り組みを通して獲得したファインチューニングに関する知見を活かし、特定業務に特化させた各社独自のLLM開発をご支援いたします。 -
オンプレ環境におけるLLMの開発
本取り組みでは、オンプレ環境上でLLMのファインチューニング並びに評価を行いました。
そこで当社は本取り組みを通して獲得したオンプレ開発に関する知見を活かし、工場内など特に高いセキュリティ要件が求められるクローズドな環境内でのLLM活用をご支援いたします。
■ 日本特許翻訳株式会社について
日本特許翻訳株式会社は、特許や知的財産関連の分野に特化した高精度な機械翻訳システムを提供する企業です。独自の翻訳支援ツールを活用し、特許翻訳を迅速かつ正確に行い、企業の知的財産活動をサポートしています。
本社所在地 :東京都中央区日本橋兜町17-2 兜町第六葉山ビル4F
■ 株式会社エムニについて
株式会社エムニは「AIで働く環境を幸せに、世界にワクワクを」というミッションのもと、製造業を中心に各企業ごとにカスタマイズされた『オーダーメイドAI』の開発及び導入支援に取り組んでいます。京都大学大学院でAI研究に従事したメンバーや、東京大学院工学系研究科松尾・岩澤研究室とビジョンを共有する松尾研究所でAI社会実装に携わったメンバーが、貴社に最適なAIを提供いたします。

|
会社名 |
株式会社エムニ |
|
代表 |
下野祐太 |
|
所在地 |
東京都文京区本郷6丁目25-14 |
|
コーポレートサイト |
|
|
メールアドレス |
yuta.shimono@emuniinc.jp |
|
連絡先 |
090-9276-6995 |
